
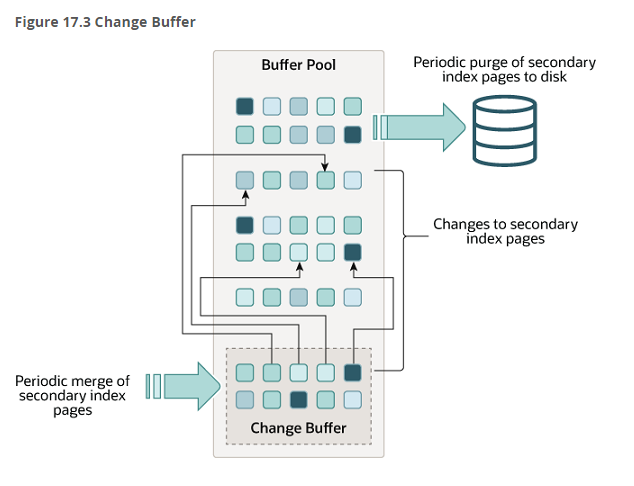
在 MySQL5.5 之前,叫插入缓冲(Insert Buffer),只针对 INSERT 做了优化;现在对 DELETE 和 UPDATE 也有效,叫做写缓冲(Change Buffer)。它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(Buffer Changes),等未来数据被读取时,再将数据合并(Merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘 IO,提升数据库性能。
数据的修改分为两个情况:
当修改的数据页在缓冲池时
通过 LRU、Flush List 的管理,数据库不是直接写入磁盘中,是先将 redo log 写入到磁盘,再通过 checkpoint 机制,将这些 “脏数据页” 同步地写入磁盘,等于是将这期间发生的 n 次的落盘合并成了一次落盘。因为有 redo log 是落盘的,所以即使数据库崩溃,缓存中的数据页全部丢失,也可以通过 redo log 将这些数据页找回来。
redo log 是数据库用来在崩溃的时候进行数据恢复的日志,redo log 的写入策略可以通过参数控制,并不一定是每一次写操作之后立即落盘 redo log,在部分参数下,redo log 可能是每秒集中写入一次,也有可能采取其他落盘策略,但是无论采用什么方式,redo log 的量都是不会减少的,与数据写入的覆盖性不同,后一条 redo log 是不会覆盖前一条的,而是增量形式的,因此写 redo log 的操作,等同于是对磁盘某一小块区域的顺序 I/O,而不像数据落盘一样的随机 IO 在磁盘里写入,需要磁盘在多个地方移动磁头。所以 redo log 的落盘是 IO 操作当中消耗较少的一种,比数据直接刷回磁盘要优很多。
当修改的数据页不在缓冲池时,不用写缓冲至少需要下面的三步:
先把需要的索引页,从磁盘加载到缓冲池,一次磁盘随机读操作;
修改缓冲池中的页,一次内存操作;
写入 redo log ,一次磁盘顺序写操作;
在没有命中缓冲池的时候,至少多产生一次磁盘 IO,对于写多读少的业务场景,性能损耗是很高的
加入写缓冲优化后,流程优化为:
在写缓冲中记录这个操作,一次内存操作;
写入 redo log,一次磁盘顺序写操作;
其性能与这个索引页在缓冲池中,相近。
如何保证数据的一致性?
数据库异常奔溃,能够从 redo log 中恢复数据;
写缓冲不只是一个内存结构,它也会被定期刷盘到写缓冲系统表空间;
数据读取时,有另外的流程,将数据合并到缓冲池;
下一次读到该索引页:
载入索引页,缓冲池未命中,这次磁盘 IO 不可避免;
从写缓冲读取相关信息;
恢复索引页,放到缓冲池 LRU 和 Flush 里;(在真正被读取时,才会被加载到缓冲池中)
为什么写缓冲优化,仅适用于非唯一普通索引页呢?
InnoDB 里有聚集索引(Clustered Index)) 和普通索引 (Secondary Index) 两种。如果索引设置了唯一(Unique)属性,在 进行修改操作 时, InnoDB 必须进行唯一性检查 。也就是说, 索引页即使不在缓冲池,磁盘上的页读取无法避免(否则怎么校验是否唯一!?)
此时就应该直接把相应的页放入缓冲池再进行修改。
除了数据页被访问,还有哪些场景会触发刷写缓冲中的数据呢?
有一个后台线程,会认为数据库空闲时;
数据库缓冲池不够用时;
数据库正常关闭时;
redo log 写满时;(几乎不会出现 redo log 写满,此时整个数据库处于无法写入的不可用状态)
什么业务场景,适合开启 InnoDB 的写缓冲机制?
数据库大部分是非唯一索引;
业务是写多读少,或者不是写后立刻读取;

发表评论