首页
JVM
并发编程
设计模式
消息队列
数据库
项目场景
开发工具
分布式
微服务
spring
搜索
mysql
mysql
0
分库分表相关的问题
2024.09.11 |
cuithink
| 96次围观
(1)为什么要进行分库操作?分库指的是将存储在一个数据库中的数据拆分到多个数据库中进行存储。主要原因如下:1、性能提升:随着业务量的增长,单一数据库可能会面临性能瓶颈。分库可以将数据和请求分散到多个数据库上,从而提高系统的吞吐量和响应时间2、容量扩展:单一数据库可能收到硬件资源(磁盘,CPU,内存)的限制,分库可以将数据分散到多个数据库上,从而突破这些限制,实现容量的线性扩展3、可靠性提升:分库可以提高系统的可靠性。当某个数据库出现故障时,其他数据库仍然可以正常工作,从而保证...
mysql
0
mysql之Tablespace结构
2024.09.11 |
cuithink
| 92次围观
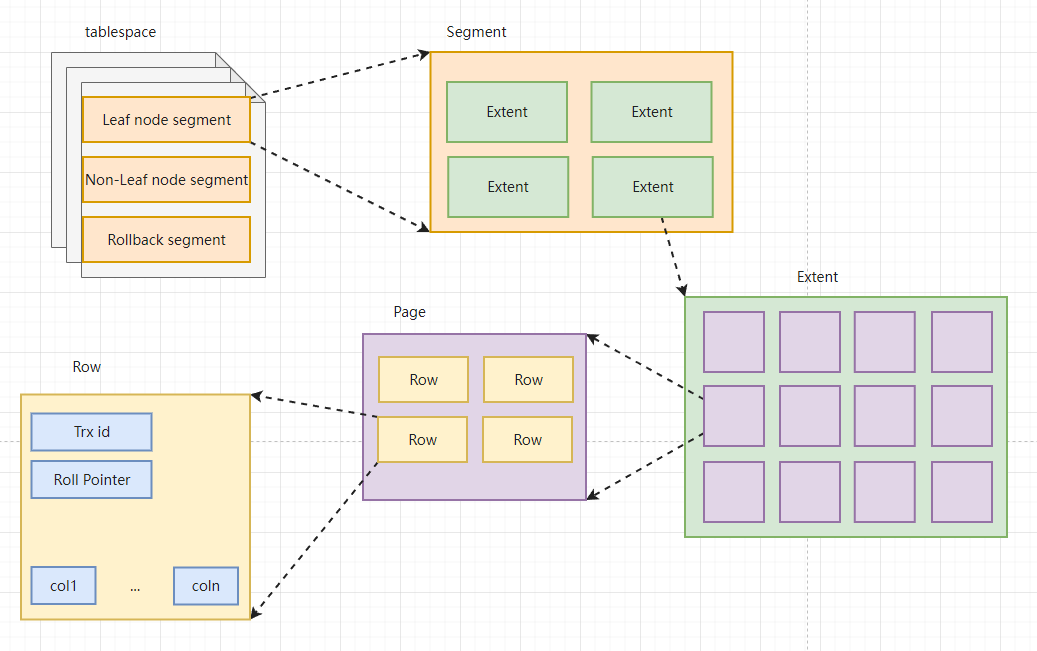
从Innodb存储引擎的逻辑结构看,所有的数据都被逻辑地放在一个空间内,称之为表空间,表空间又由 段(segment),区(extent),页(page)组成。页在一些文档中有时候也称为块(block) ,如下图所示:段(segment)区(extent)页(page)表空间由段组成,常见的段有数据段、索引段、回滚段等。InnoDB存储引擎表是索引组织的,因此数据即索引,索引即数据。数据段即为B+树的叶子结点,索引段即为B+树的非索引结点。在InnoDB存储引擎中对段的管理都...
mysql
0
mysql-磁盘上存储结构
2024.09.11 |
cuithink
| 87次围观
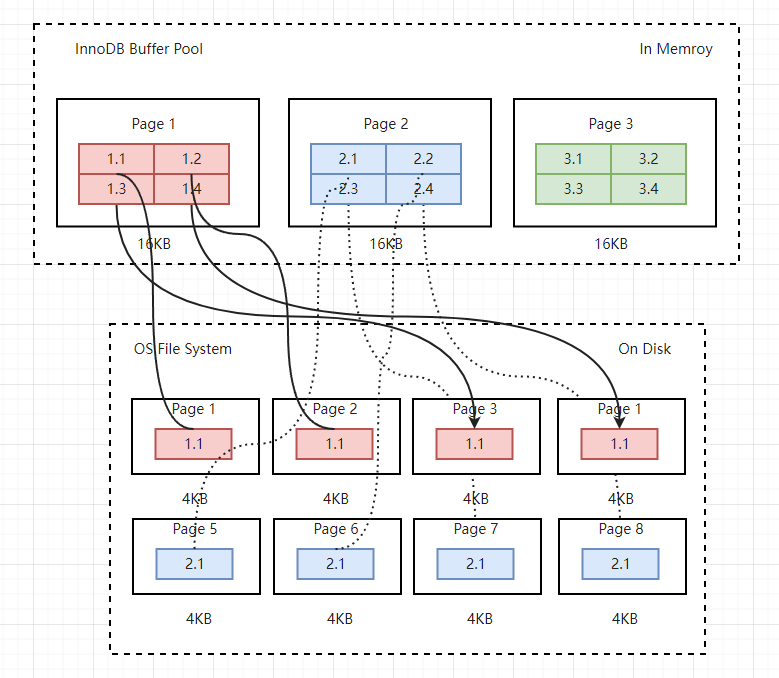
Innodb存储引擎的逻辑存储结构是将所有的数据都逻辑的放在了一个空间中,这个空间中的文件就是实际存在的物理文件(ibd文件)。默认情况下,一个表占用一个表空间,表空间可以看做是Innodb存储引擎逻辑结构的最高层,所有的数据都放在表空间中。表空间分为系统表空间,临时表空间,通用表空间,undo表空间和独立表空间。系统表空间 系统表空间可以对应文件系统上一个或多个实际的文件,默认情况下, InnoDB 会在数据目录下创建一个名为ibdata1,大小为 12M 的文件,这个文件...
mysql
0
mysql之Log Buffer
2024.09.11 |
cuithink
| 15次围观
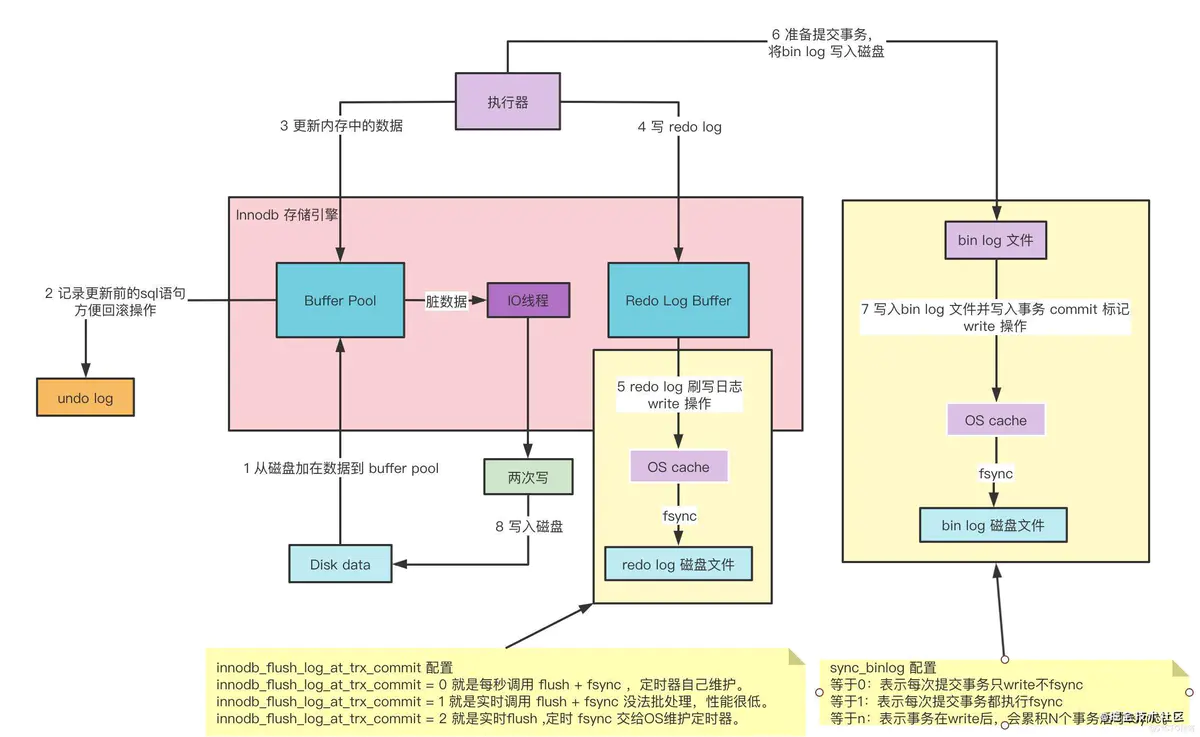
Log Buffer是存储要写入磁盘上的日志文件的数据的内存区域,日志缓冲区的大小由innodb_log_buffer_size变量决定的,默认是16M,日志缓冲区的内容定期刷新到磁盘。较大的日志缓冲区可以运行大型事务,而无需再事务提交之前将重做日志数据写入磁盘。因此,如果有更新、插入或者删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘IO。可以通过 innodb_flush_log_at_trx_commit参数来控制如何将日志缓冲区的内容写入并刷新到磁盘,默认是11、...
mysql
0
mysql之Change Buffer
2024.08.11 |
cuithink
| 99次围观
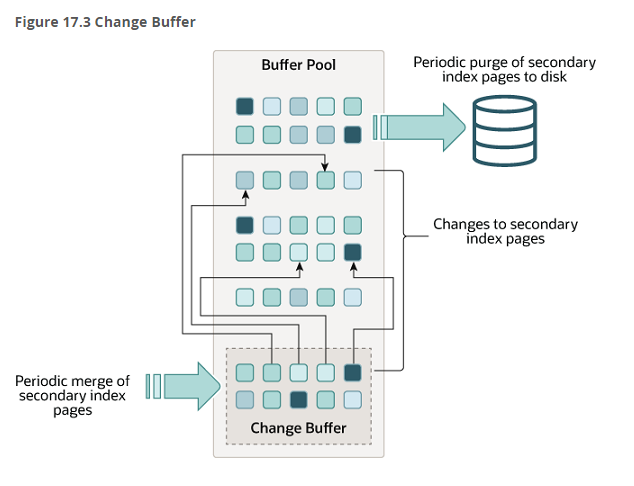
在 MySQL5.5 之前,叫插入缓冲(Insert Buffer),只针对 INSERT 做了优化;现在对 DELETE 和 UPDATE 也有效,叫做写缓冲(Change Buffer)。它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(Buffer Changes),等未来数据被读取时,再将数据合并(Merge)恢复到缓冲池中的技术。写缓冲的...
mysql
0
mysql之buffer pool
2024.08.11 |
cuithink
| 24次围观
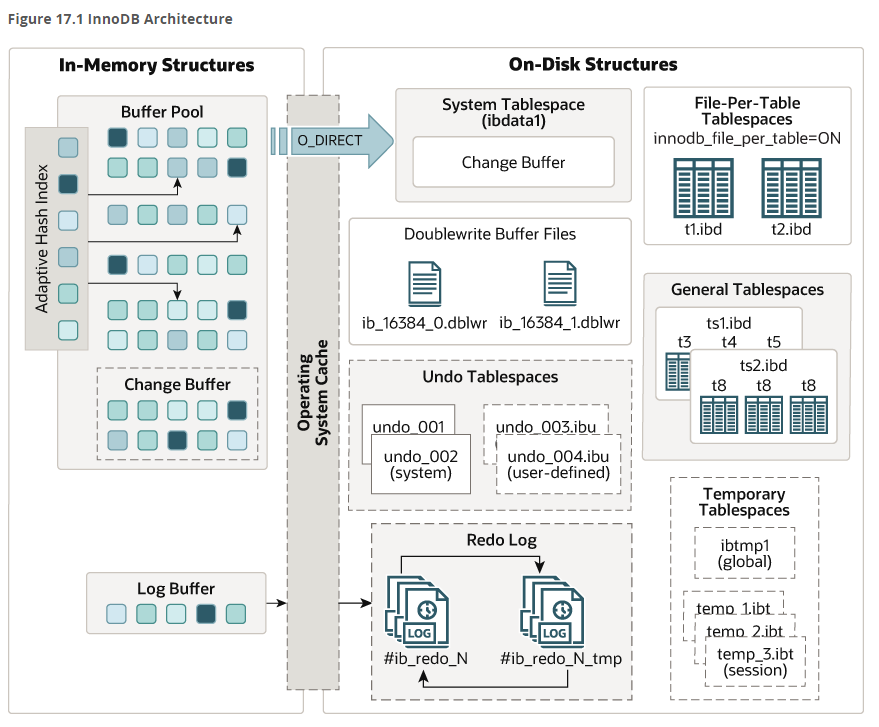
在mysql的早期版本中,默认的存储引擎是Myisam,后来由Innobase Oy公司开发出innodb,作为插件引擎集成在mysql中,因其出色的性能在mysql5.5版本之后开始作为默认的存储引擎。Innodb是第一个完整支持ACID事务的mysql存储引擎,特点是行锁设计,支持MVCC,支持外键,提供一致性非锁定读,非常适合OLTP场景。innodb存储引擎架构包含内存结构和磁盘结构两大部分,整体架构图如下:In-Memory StructureBuffer Pool...
mysql
0
mysql存储引擎初识
2024.08.11 |
cuithink
| 35次围观
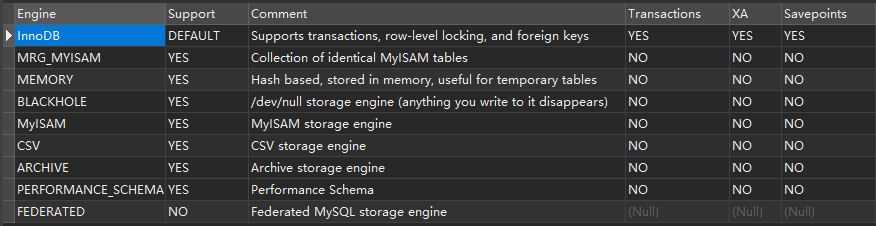
存储引擎 在MYSQL中,我们看到的数据是以表的方式进行展示,但是实际在进行存储的时候以文件的方式进行存储,不同类型的表在磁盘中会有不同的组织和存储形式。 不同的数据文件在磁盘的不同组织形式。 通过执行show engines可以查看MYSQL中支持的存储引擎:MyISAM(3个文件) These tables have a small footprint. Table-level locking limits the performance in read/wri...
mysql
0
mysql架构-客户端&服务端
2024.08.11 |
cuithink
| 15次围观
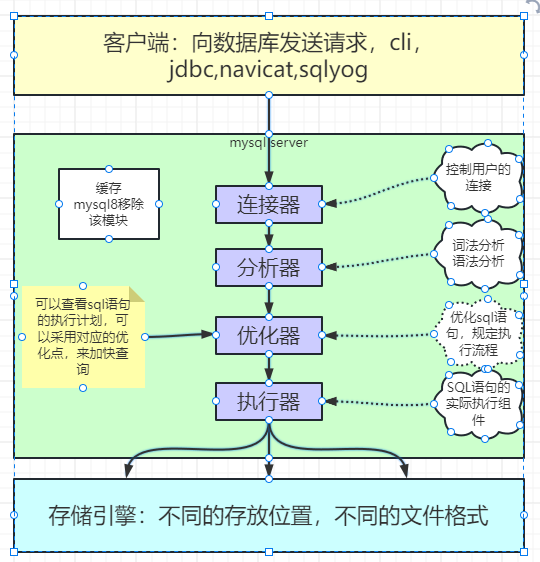
一般情况下,我们在进行MYSQL整体架构描述的时候分为三层,分别是客户端,服务端,存储引擎,如下图所示:1、客户端 客户端主要用于向MYSQL的服务端发送SQL语句,我们使用的cli,jdbc,可视化工具都可以称之为客户端2、服务端 MYSQL的服务端主要是对外提供MYSQL的服务,主要包含四个组件:连接器,分析器,优化器,执行器连接器 在MYSQL中,支持多种通信协议,主要有以下分类: (1)TCP/IP协议,任何编程语言在进行数据库连接的时候基本都是通过TCP协议...
mysql
0
mysql索引(二)
2024.08.11 |
cuithink
| 16次围观
2、索引有哪些分类? 索引的分类要按照不同的角度去进行分类: 1、从数据结构的角度可以分为B+树索引、哈希索引、FULLTEXT索引、R-Tree索引(用于对GIS数据创建SPATIAL索引) 2、从物理存储角度可以分为聚簇索引和非聚簇索引 3、从逻辑角度可以分为主键索引、普通索引、唯一索引、组合索引3、聚簇索引与非聚簇索引 在MYSQL的innodb存储引擎中,数据在进行插入的时候必须要跟某一个索引列绑定在一起进行存储,如果有主键,那么选择主键,如果没有主键,那么...
mysql
0
mysql索引(一)
2024.08.11 |
cuithink
| 55次围观
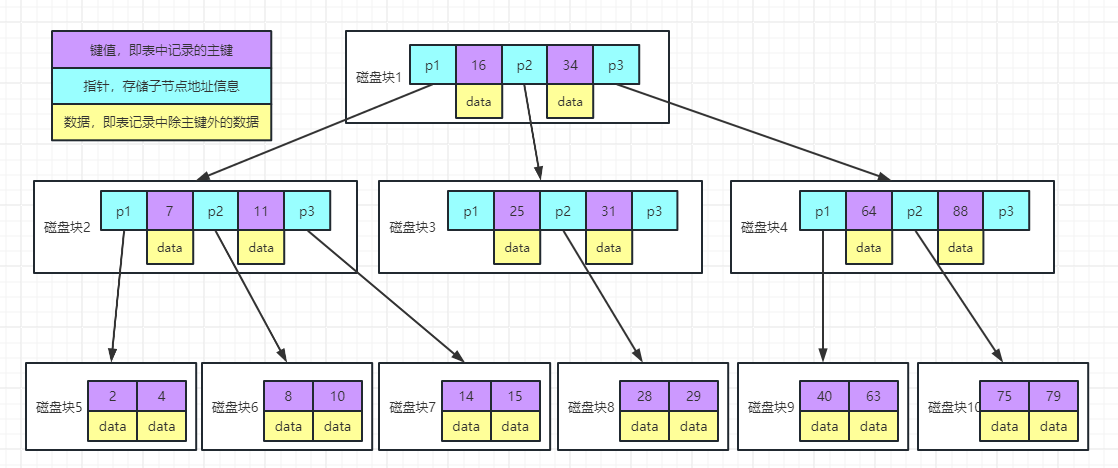
1、谈一下你对于mysql索引的理解?(为什么mysql要选择B+树来存储索引) mysql的索引选择B+树作为数据结构来进行存储,使用B+树的本质原因在于可以减少IO次数,提高查询的效率,简单点来说就是可以保证在树的高度不变的情况下可以存储更多的数据: 1、在MYSQL的数据库中,表的真实数据和索引数据都是存储在磁盘中,我们在进行数据读写的时候必然涉及到IO的问题,IO本质上来说是硬件方面的问题,但是我们在做索引设计的时候肯定要尽可能的考虑如何提高IO的效率,一般来说,...
1
2
下一页
尾页
热门文章
1
MVCC多版本并发控制(一)
2
适配器模式
3
redis 简图
4
idea快捷键
5
线程的创建
6
mysql之Change Buffer
7
建造者模式(Builder)
8
G1垃圾回收器介绍
9
分库分表相关的问题
随机文章
代理模式
分布式事务
mysql之Log Buffer
sentinel(二)
Kafka基本概念
观察者模式
spring事务
适配器模式
kafka基本使用
最近发表
spring循环依赖
SpringBoot启动流程
分布式事务-TCC&Saga模式
分布式事务-seata XA模式
分布式事务-seata AT模式
分布式事务
分布式幂等性如何设计
分布式ID生成有几种方案
分布式锁(二)
分布式锁
网站分类
未分类
JVM
并发编程
设计模式
消息队列
kafka
rabbitmq
数据库
redis
mysql
项目场景
开发工具
分布式
微服务
spring
文章归档
2024年10月 (57)
2024年9月 (14)
2024年8月 (6)
2024年7月 (4)